
The Cloud's Final Frontier: Orbital Data Centers and the Future of Earth Observation
A deep dive into why Earth Observation may become the first real proving ground for in-orbit compute - from Starcloud-1 to Google’s Suncatcher.

On a hot August afternoon in the early 2040s, a wildfire flares in a parched valley in the Mediterranean. A single satellite snaps a frame; just one tile in the endless strip of data silently collecting in low-Earth orbit.
But this time, the image never touches a ground station.
Instead, it veers sideways, into a shoebox-sized rack of GPUs bolted to the inside of another satellite. Within seconds, an onboard model flags a new ignition, cross-checks with wind and fuel maps, and beams down a handful of bytes: coordinates, confidence, predicted spread.
On the fire command center’s screen, the alert looks almost trivial; just one more icon on a map.
Behind it, though, is the question more people in cloud and space are beginning to ask out loud:
Are we really going to build data centers in space?
And if we do… is that an act of climate responsibility, or simply a very expensive way of exporting our problems above the Kármán line?
Earth Observation isn’t the sole force pushing compute off-planet, but it may be the first domain where the case becomes impossible to ignore: too much data, too little bandwidth, too slow a path from pixel to decision. This essay argues that EO is uniquely positioned to become the first scalable proving ground for orbital compute: its bottlenecks are structural, its latency demands are high, and no other domain benefits as much from processing data close to the sensor.
The rest of this essay is about why this “radical” idea is on the table at all, what it could unlock for Earth Observation, and what’s standing squarely in the way.

Why we’re even entertaining such a wild idea
Terrestrial data centers already consume a noticeable slice of global electricity. By 2030, US data centers alone could consume around 9% of the country’s electricity. This rising consumption, fueled by AI training and inference, creates a genuine energy policy problem. What used to be “big IT loads” are now grid-scale industrial assets. The same machines that generate photorealistic cats and power large language models are now competing with homes, factories, and public transit for electricity.
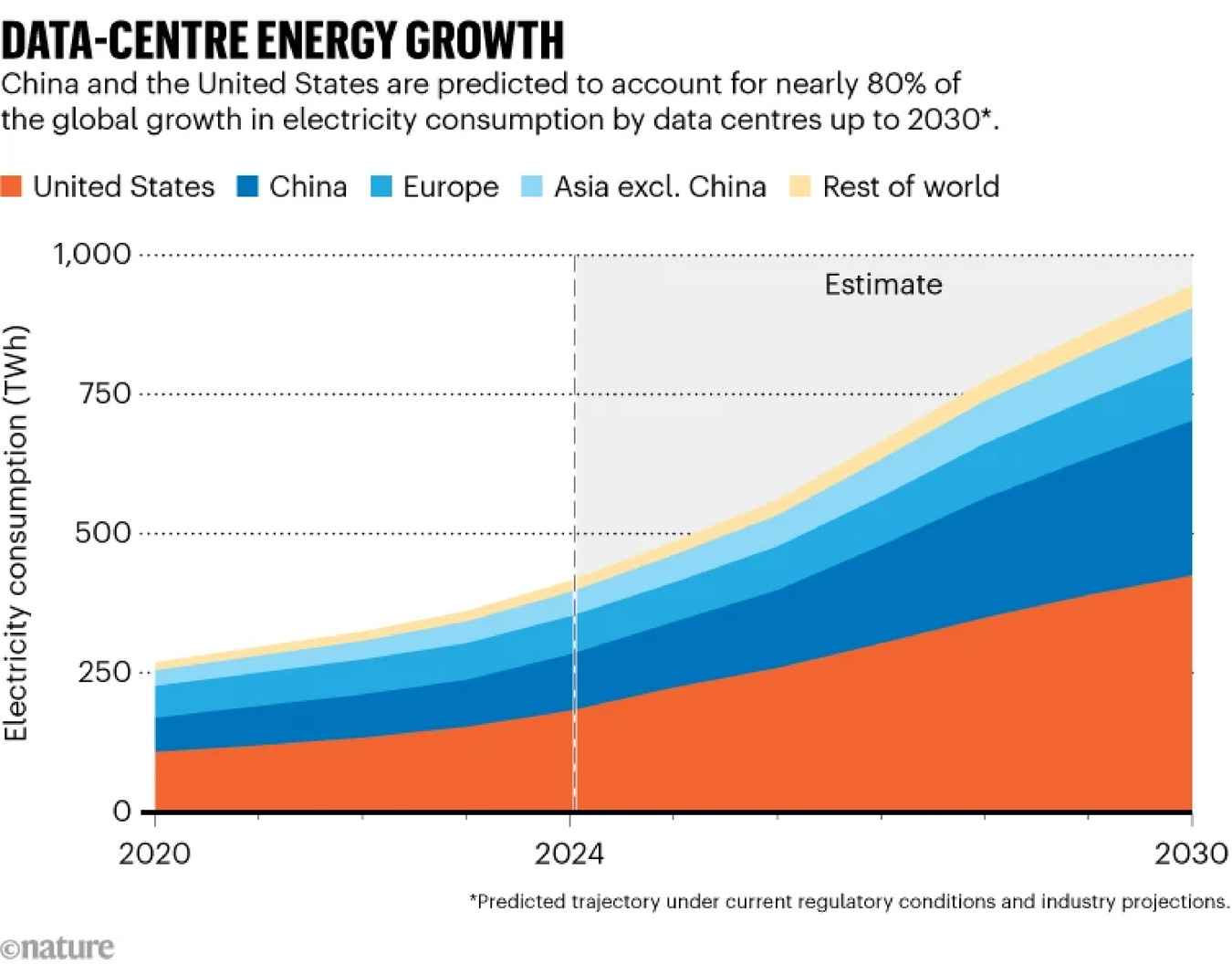
This might sound familiar to anyone tracking the sector. Utilities cannot bring multi-hundred-megawatt capacity online fast enough. Some operators — like Microsoft — have been reported to stockpile GPUs that sit idle simply because they lack the power or the “warm shells” to plug them in. Others quietly wheel in temporary gas generators just to get clusters running because the grid cannot yet carry the load.
Cooling multiplies the issue. Hyperscale facilities consume millions of litres of water a day to keep their processors within comfortable temperatures. In regions already struggling with drought, this is not just unpopular, it is politically explosive. Add in the reality that many of these sites sit on precious land near metropolitan areas, and you start to see why permits are slowing, communities are pushing back, and expansion plans look increasingly like a geopolitical game of Tetris.
Meanwhile, the orbital segment faces its own growing constraints. High-resolution optical constellations, SAR fleets, hyperspectral demonstrators, thermal missions, GNSS reflectometry, atmospheric sounders; they are producing exponentially more data than the Radio Frequency (RF) downlink infrastructure was ever designed to support.
The sensors are scaling exponentially; the downlink is scaling linearly. Petabytes of data are being produced every day and ground stations strain to keep up. Latency from acquisition to usable product stretches into hours and, for some use cases, days. For climate and disaster risk, that lag is not an inconvenience; it’s a failure of design.
Put simply: on Earth, we are running out of room, power, and political patience for more data centers. In space, we are running out of time and bandwidth to move and process the data we already collect.
And somewhere between an overburdened grid below and an overburdened downlink above, one group of people began sketching another option:
What if we just put the data center in orbit?
What if compute lived closer to the sensors, and closer to the only power source that scales indefinitely: sunlight?
The Orbital Solution: A New Geography for the Cloud
Reframing space as an industrial environment rather than a distant frontier makes orbital data centers feel less like science fiction and more like a deliberate reallocation of infrastructure.
The physical argument begins with sunlight. On Earth, solar panels contend with atmosphere, clouds, weather, and the simple fact of night. Their capacity factor, the ratio between what they could produce in theory and what they actually produce over time, hovers around a few tens of percent. But in carefully chosen sun-synchronous orbits, panels can achieve capacity factors exceeding 90%, with stable irradiance and minimal intermittency. A satellite can surf the terminator and remain in near-constant daylight.
It is no surprise that some of the most visible proponents of this vision are the people staring at the scaling curves of AI. Jeff Bezos has spoken openly about gigawatt-scale data centers in space within a few decades. Tom Mueller, who helped architect the early SpaceX engines, has argued that if we want the benefits of compute without burning the planet in the process, a meaningful fraction of heavy compute will eventually need to move off-world.
For most domains, that still feels like a leap. For Earth Observation, which already lives half in orbit and half on the ground, the leap is smaller. We already fly constellations, already generate petabytes overhead, and already treat orbit as part of the data pipeline. Giving these sensors access to compute in orbit becomes less a revolution than an overdue symmetry: sensing up there, thinking up there.
A Revolution in Earth Observation: From Bent Pipe to the In-Orbit Compute Fabric
Earth Observation is already indispensable for managing climate risk, food security, and disaster response. Yet the architecture we still rely on to turn satellite data into decisions is, in many ways, fundamentally 20th-century.
For decades, EO has followed a bent-pipe model: satellites acquire data, store it, and then offload everything to ground stations whenever they pass overhead. From there, the data is transferred into data centers or cloud regions, indexed, calibrated, processed, analysed, and eventually turned into maps, alerts, or time series. At a moderate scale, this works. At the scale of modern and planned constellations, it starts to crack.
Meanwhile, the terrestrial ground station infrastructure, which serves as the traditional backbone for satellite operations, faces immense strain as the volume of space-generated data explodes. These stations are indispensable; without them, a satellite cannot update software, receive commands, or shed the terabytes it accumulates each day. Agencies like the USGS, NASA, and NOAA rely on strategic polar stations, such as Norway’s SvalSat, as these are the only spots where satellites in polar orbits can downlink their data and receive commands on every trip around Earth. However, this dependence has created a critical bottleneck: there are only so many passes per day, only so much RF spectrum to go around, and only so much contact time available for a fleet that is expanding far faster than the ground segment built to serve it. With the number of satellites in Low Earth Orbit (LEO) expected to increase by 190% within the next decade, the RF Ground Station infrastructure is predicted to be strained, affecting data quality and reducing the available bandwidth time for each satellite. This reliance also introduces geopolitical and physical vulnerabilities, as demonstrated by events like cable breaks, which can cause delays of several hours for critical datasets, directly affecting applications like weather forecast and civil protection.
To address this reliance and ground station bottleneck, Orbital Edge Computing (OEC) proposes a different flow, shifting the paradigm from the “bent-pipe” model that has defined EO for half a century. Instead of relying on the ground as the first place where data becomes information, OEC pushes part of the processing pipeline back into space. High-throughput radio and optical links, such as Optical Intersatellite Links (OISLs), ferry raw sensor data sideways; from imagers to orbital compute nodes. There, AI models segment, classify, detect anomalies, estimate physical variables, and decide what is worth keeping. The result is not a continuous flood of scenes to Earth, but a curated stream of maps, alerts, and derived products that are far more actionable and far less burdensome to downlink.
The difference for EO missions is more than marginal. Fires can be detected and confirmed in near-real-time, with predicted spread calculated before the first downlink pass even becomes available. Flooded areas can be mapped from SAR data and compared with building footprints while the orbit is still overhead. Cloud-covered scenes can be discarded on-orbit instead of clogging the ground segment with useless scenes. Crop stress indices can be derived while the constellation is still over the fields, and only the derived products ever leave space. In a fire control center, a civil protection room, or an agricultural advisory service, the user sees the same thing — a dot on a map, a polygon, a time series — but behind it the distance between sensing and decision is shorter and far more efficient.
Crucially, once satellites and orbital data centers can talk to each other, they can also begin to task each other. The jargon for this is “tip-and-cue.” A thermal satellite detecting a suspicious hotspot can tip a higher-resolution optical satellite to capture a follow-up pass. A SAR constellation can cue a high-resolution optical satellite when it sees structural change in a wetland or a suspect vessel in a shipping lane. In a mature orbital compute layer, those tips and cues need not wait for a human operator; they become machine-to-machine negotiations, executed at orbital timescales and governed by policy, priority, and mission logic rather than human reaction speed.
Seen from that angle, orbital data centers are not just remote cloud regions in exotic locations. They are where the EO system begins to behave like a distributed orbital compute layer: sensing locally, integrating globally, and acting — by retasking sensors, escalating alerts, or thinning data streams — without waiting for the ground infrastructure to dictate the tempo of the observation cycle.
The First Wave of Orbital Compute Infrastructure
The early market has arrived: funding rounds, demonstrator missions, feasibility studies, and national strategies are already in motion.
In China, ADA Space is pursuing the most aggressively scaled vision to date. Its Three Body Computing Constellation launched its first 12 satellites in May 2025, each equipped with 100 Gb/s optical links and on-orbit accelerators delivering up to 744 trillion operations per second (TOPS). This “first wave” is designed as the seed of a far larger architecture: a 2,800-satellite distributed supercomputer in LEO. For China, this is more than technical ambition. It is a bid to own a strategic high ground where AI, sensing, and communications converge; a national asset as much as a commercial platform.
In the United States, private enterprise and Big Tech are pursuing parallel “moonshot” approaches. Among the commercial leaders is the US startup Starcloud (formerly Lumen Orbit), which treats space not as a novelty but as the only environment capable of sustaining AI’s power appetite. In November 2025, Starcloud launched Starcloud-1, carrying an NVIDIA H100; a chip nearly two orders of magnitude more powerful than anything previously flown. The mission tests wildfire detection, crop monitoring, and vessel identification models running in orbit. But Starcloud’s long-term vision is even more ambitious: a five-gigawatt orbital hypercluster powered by a solar array four square kilometers across, with second-generation satellites carrying Blackwell-class chips expected as early as 2026.
Axiom Space is taking a different route. Rather than standalone compute nodes, it is integrating orbital data center capability directly into Axiom Station, the commercial successor to the ISS. Axiom has flown both an AWS Snowcone and its AxDCU-1 prototype, and plans to field its first operational ODC nodes in 2025. Partnerships with Red Hat and Kepler suggest a focus on national security workloads, autonomous in-orbit R&D, and a steadily expanding commercial edge computing ecosystem.
The cloud hyperscalers are also entering the field. Google’s Project Suncatcher positions orbit as a “research moonshot” to stretch the scaling laws of machine learning beyond the limits of terrestrial energy and cooling. Instead of NVIDIA hardware, Google intends to fly its own Trillium-generation TPUs, with two prototypes scheduled for launch by 2027 in partnership with Planet.
Across the Atlantic, Europe is framing the challenge through policy; one of sovereignty and climate alignment. The ASCEND feasibility study, led by Thales Alenia Space, argues that orbital compute can support Europe’s net-zero ambitions while strengthening digital independence. The roadmap moves from a 50-kilowatt demonstrator around 2031 to a one-gigawatt facility by mid-century, with strong emphasis on lifecycle emissions, regulatory guardrails, and European control of data processed overhead.
Despite their different ambitions, all of these programs intersect with Earth Observation, which makes EO the most immediate proving ground for in-orbit compute. Whether the driver is national security, AI scaling, or digital sovereignty, EO workloads are the first to benefit from moving processing closer to the source.
Yet turning these ambitions into infrastructure requires more than technical daring. It requires confronting the physical and regulatory realities that no strategy document can gloss over. Markets may be signaling demand, governments may see sovereignty and security advantages, and companies may race to stake orbital territory, but none of that suspends the constraints of heat, radiation, mass, and maintainability. Before orbital compute can mature from a geopolitical aspiration into a reliable layer of critical infrastructure, it must first pass through the hard bottlenecks that space itself imposes.
The Hard Challenges: When Physics Pushes Back
If the story ended there, this essay would be a press release. In reality, orbital data centers collide head-on with constraints defined entirely by physics.
The first is thermal management. Space is indeed cold, but it is also a vacuum. On Earth, data centers lean heavily on convection; fans, chilled water, and heat exchangers move energy away from hot components. In orbit there is no air and no water, only radiation. The Stefan–Boltzmann law sets the fundamental limit on how much heat a surface can radiate at a given temperature and emissivity. To dissipate megawatts of heat without running your radiators at dangerously high temperatures, you need radiating surfaces measured in the thousands of square metres, and you need structure, coolant loops, deployment mechanisms, and careful pointing controls to make them work. The result is that the mass of the cooling system can easily equal or exceed the mass of the compute it is cooling.
Power density suffers as a result. On the ground, with immersion and advanced liquid cooling, designers are pushing 30-100 kilowatts per rack and dreaming of more. In orbit, realistic studies suggest that 10-20 kilowatts per rack will be closer to the practical ceiling. Every extra GPU in a thermal design comes with a penalty in area and mass.
The second hard constraint is radiation. Outside the atmosphere and magnetosphere, electronics are exposed to galactic cosmic rays, solar particle events, and the radiation spikes associated with the South Atlantic Anomaly. These cause long-term radiation damage, measured as total ionizing dose, and also trigger unpredictable single-event effects; bit flips in memory, latch-ups in logic, occasional fatal damage to components. Experiments on the International Space Station and other missions have shown unexpectedly high failure rates among commercial solid-state drives flown with minimal protection. Even purpose-designed chips, like newer AI accelerators, have shown surprising vulnerabilities in their high-bandwidth memory subsystems under test.
Mitigating these effects is possible but never free. Shielding adds mass. Redundancy multiplies cost and increases system complexity. Radiation-hardened parts are often generations behind their terrestrial cousins in performance and can be an order of magnitude more expensive.
Storage is where these constraints intersect most sharply. Spinning disks are too fragile and too heavy to fly. Solid-state drives are more robust mechanically, but their dense flash cells and controllers present large targets for radiation. Aggressive error correction, scrubbing, and replication can mask many faults, but the underlying physics does not go away.
Finally, there is the simple fact of distance. Once a data center is in orbit, you cannot send a technician with a flashlight and a spare drive at three in the morning. Everything — hardware, software, and operations — has to be designed from the start for fault tolerance, autonomous recovery, modular replacement, and eventually, robotic servicing. And everything that is not deorbited responsibly becomes part of a growing cloud of debris that threatens the very constellations that orbital compute is meant to serve.
These are not abstract worries; they define the physical boundaries of what can be built. Within those boundaries, though, there is still room for careful engineering and meaningful progress.
The Easier Challenges and the Emerging Enablers
Not all obstacles are laws of nature. Some are matters of engineering maturity and here the picture is more optimistic.
Virtualization is a good example. On Earth, we treat hypervisors and virtual machines as tools for flexibility and utilization. In orbit, they become tools for survival. By inserting a hypervisor such as Xen between the hardware and the operating systems, engineers can carve the processor into strongly isolated domains. Flight software and platform control sit in one or more real-time VMs, pinned to dedicated cores with strict guarantees. EO workloads — fire detection, ship tracking, change detection, even tenant-specific models — run in other VMs that can be restarted, throttled, or migrated without endangering the satellite’s basic functions.
Experiments on representative multi-core SoCs have shown that this kind of configuration can deliver both low-latency, low-jitter behavior for critical tasks and robust containment of badly behaved or heavily loaded workloads. In practical terms, that means:
A runaway ML experiment cannot starve the altitude control loop. A third-party EO tenant cannot crash the mission by accident. A container processing flood extents cannot quietly monopolise resources needed for station-keeping. The result is an orbital compute node that behaves less like a monolithic system where everything shares the same failure points and more like a small in-orbit cluster, where mixed-criticality workloads run side by side without the risk of failing together.
Communications technology is following a similar arc. Optical inter-satellite links, once exotic, are becoming standard in large constellations. For EO and orbital compute, they form the high-bandwidth backbone of the system. They allow imaging satellites to dump data to compute nodes that are not directly overhead a ground station. They allow those nodes to share intermediate products and models among themselves. They carry tip-and-cue messages — machine-to-machine tasking instructions — connecting sensors and compute into a dynamic, reconfigurable sensor-web.
Launch costs and on-orbit servicing sit in a fuzzier but encouraging category. Reusable rockets have already driven the price per kilogram to orbit down dramatically compared to the shuttle era. Fully reusable systems, if they reach operational maturity, may push costs below the critical thresholds where a 10-year total cost of ownership for orbital compute starts to compete with the energy and infrastructure cost of high-end terrestrial facilities. Robotic servicers are being tested that can refuel, reposition, and eventually repair or upgrade satellites. Taken together, these developments do not make orbital data centers cheap, but they make them less absurd.
None of this removes the underlying physical limits. It simply reframes the problem: from “infeasible” to “viable for certain workloads”, provided the design respects those constraints.
Uncertainties in the High Ground: Law, Governance, and Control
Even if engineers manage to solve or at least squeeze these technical problems, there is still the quieter question of how an orbital cloud fits into our legal and political frameworks.
Space law as it stands was not written with data centers in mind. States remain responsible for objects they launch or authorise. Liability for damage is written into treaties. But where does data jurisdiction live when the processors are in orbit? If an EO company based in one country processes imagery of critical infrastructure from another country on a platform built and launched by a third, whose laws apply — and who has the right to inspect, regulate, or restrict it? If tip-and-cue chains autonomously retask satellites over a sensitive region, who is accountable for the action: the operator, the algorithm, the state that licensed the platform, or the tenant whose model initiated the cue?
Regulators are only beginning to grapple with terrestrial questions of data residency and sovereignty. Adding an orbital layer will not simplify that. For EO, which already sits in the sensitive space between transparency and surveillance, the arrival of orbital compute and autonomous machine-to-machine tasking will sharpen old tensions and create new ones.
Environmental governance is another open front. If lifecycle emissions from launch and re-entry turn out to be significant contributors to warming or ozone depletion, it is hard to imagine that large orbital compute constellations will escape scrutiny. One can easily foresee permitting regimes that require full lifecycle climate accounting, mitigation plans, or even offsets for launch and re-entry footprints; mirroring, at altitude, the environmental reviews that already shape terrestrial infrastructure projects.
And then there is debris. Large, long-lived structures are not trivial additions to crowded orbital shells. If multiple states and corporations deploy competing orbital compute hubs without robust end-of-life plans, the probability of collisions and cascading fragmentation grows. For EO, which depends on the long-term stability of low-Earth orbit, this isn’t a distant or theoretical issue but a hard operational constraint on the entire sector.
How This Future Could Look — If We Get It (Mostly) Right
Return, finally, to that fire in the Mediterranean and roll the clock forward to a plausible late-2050s.
Launch costs have fallen into the tens of dollars per kilogram. Fully reusable rockets fly often enough that adding orbital infrastructure is no longer an extraordinary undertaking but simply another predictable operational expense. On-orbit servicing has matured to the point where satellites can be refuelled, nudged into new orbits, and have modular compute “bricks” swapped out robotically. Debris rules are enforced; operators who fail to comply lose access to launch services, insurance, or the radio spectrum needed to run their satellites.
Above us, in a handful of carefully managed orbital shells, sit clusters of orbital EO compute hubs. They are not absurd mega-rings, but more modest stations: trusses, solar arrays, large radiator panels, instrument modules, and both pressurised and unpressurised racks. Each hub carries a layered stack of workloads with different criticalities. Some cores run radiation-hardened (rad-hard) control loops; others host higher-performance accelerators that are expected to live a few years before being swapped. Hypervisors carve the hardware into slices. Spacecraft control lives in one set of virtual machines, infrastructure for communications in another, high-priority EO applications in a third, and time-boxed experiment slots in a fourth.
Around these hubs, constellations of EO satellites orbit in different planes and inclinations. Optical imagers, SAR platforms, thermal sensors, GNSS reflectometry missions, atmospheric sounders, and niche scientific instruments each play their part. Some feed data directly to Earth. Many send their raw output sideways to the hubs, where it is combined with data from other sensors, from reanalysis products, from climate models, and from historical archives cached in-orbit.
Tip-and-cue has become routine. A SAR satellite noticing unusual activity in a coastal zone cues a very-high-resolution optical satellite to take a closer look on its next pass. A thermal mission detecting unusual urban hotspots at night nudges a hyperspectral sensor to sample the area for signs of industrial flaring or leaks. A flood detection model running on a hub identifies a rapidly expanding inundation area and pushes updated tasking patterns to upstream imagers to maximise coverage over the next few orbits. Much of this negotiation happens machine-to-machine, mediated by policies set on the ground but executed at orbital speed.
On Earth, the interfaces look almost disappointingly simple. Fire agencies subscribe to ignition alerts for predefined areas of interest rather than to “all imagery over this region.” River basin managers subscribe to floodplain exceedances and soil moisture anomalies instead of raw scenes. Agricultural advisory services receive updated, field-scale crop stress maps driven by models that were partially computed on-orbit and partially refined on the ground. National climate centers pull continuous, quality-controlled EO-derived indicators without seeing the terabytes of data from which they were derived.
None of this makes terrestrial data centers obsolete. Heavy model training, long-term archival, open data services, exploratory science, offline reanalysis; all of that still happens in large facilities firmly bolted to the crust. The hybrid model emerges naturally: orbit for proximity to sensors and to sunlight; Earth for depth, breadth, and the messy business of humans interrogating data.
In that world, the question is no longer whether we should put data centers in space in some abstract sense, but rather which computations genuinely belong there. The answer will not be “everything” and it will certainly not be “nothing.” It will be a moving boundary, shaped by launch costs, by policy, by climate accounting, and by the unforgiving algebra of power, bandwidth, and latency.
What seems clear already is that EO will be one of the first domains to cross that boundary in a meaningful way. The mismatch between how quickly we can see the planet change and how slowly we can respond is not going away on its own. Orbital compute, paired with autonomous tip-and-cue, strong virtualization, and honest environmental accounting, offers one of the few credible paths to closing that gap.
Used well, it can help transform an overloaded EO ecosystem into an orbital fabric that observes, interprets, and responds on operational timelines.
Used badly, it will become just another shiny, expensive distraction orbiting above a planet that never managed to align its infrastructure with its ecological and physical limits.
Ultimately, technology alone will not decide which of those futures we get. The choices we make now — about where computation happens, how we account for its costs, and which problems deserve to be addressed in orbit — will.
Further Reading & Sources
In researching this piece, I worked through several papers, feasibility studies, mission docs, technical reports, and public statements. I used NotebookLM to organise, query, and cross-reference my sources. You can explore the notebook here.
Didn't expect this take on orbital compute, but wow. Logic for processing near sensor is solid. What about the power budget for those AI models?